Code
library(tidyverse)
library(readxl)
library(infer)
theme_set(theme_bw())Pruebas de hipótesis
library(tidyverse)
library(readxl)
library(infer)
theme_set(theme_bw())datos <- read_excel("datos-disexp/datos-encuestas-historia.xlsx")
datos



ggpubr::ggqqplot(datos$promedio_acad)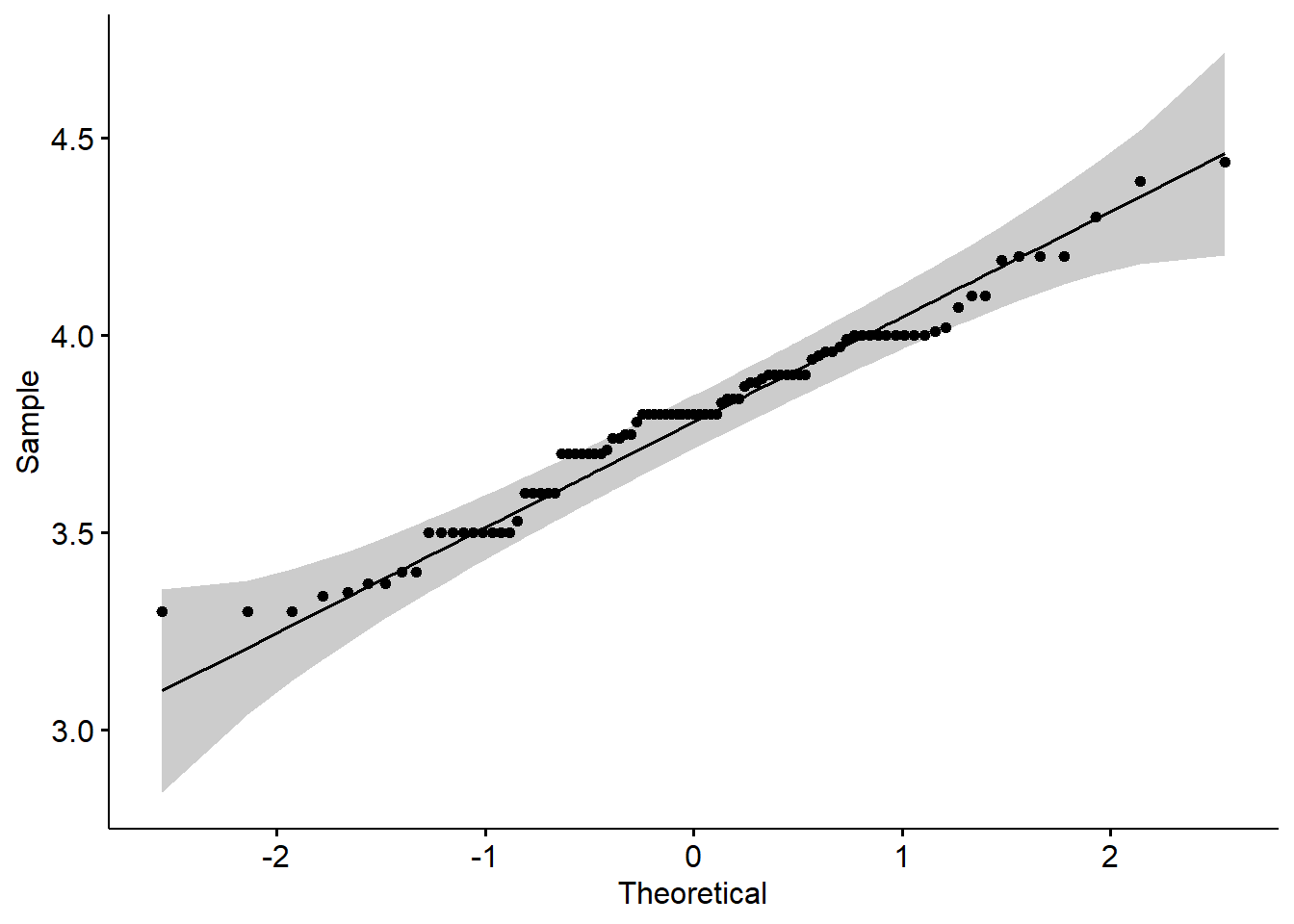
\[H_0: \mu = 3.5\]
\[H_1: \mu \neq 3.5\]
\[T = \frac{\bar{X} - \mu}{S/\sqrt{n}}\]
x_barra <- mean(datos$promedio_acad, na.rm = TRUE)
mu_referencia <- 3.5
desviacion_muestral <- sd(datos$promedio_acad, na.rm = TRUE)
raiz_n <- sqrt(nrow(datos))\[T = \frac{3.794516 - 3.5}{0.247371/9.643651} = 11.48158\]
(x_barra - mu_referencia) / (desviacion_muestral / raiz_n)[1] 11.48158
Podemos obtener los límites critícos con R:
qt(p = 0.025, df = 92, lower.tail = TRUE)[1] -1.986086qt(p = 0.025, df = 92, lower.tail = FALSE)[1] 1.986086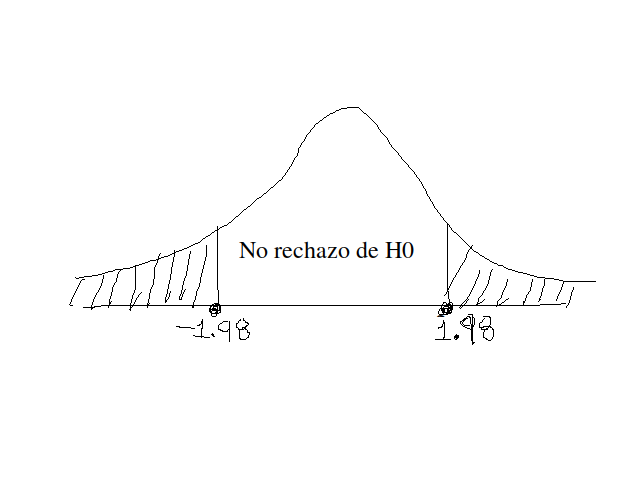
\[\bar{X} - t_{\alpha/2, n-1} \times \frac{s}{\sqrt{n}}\]
x_barra - (1.986086 * (desviacion_muestral / raiz_n))[1] 3.743571\[\bar{X} + t_{\alpha/2, n-1} \times \frac{s}{\sqrt{n}}\]
x_barra + (1.986086 * (desviacion_muestral / raiz_n))[1] 3.845462pt(q = -11.48158, df = 92, lower.tail = TRUE)[1] 9.287894e-20pt(q = 11.48158, df = 92, lower.tail = FALSE)[1] 9.287894e-209.287894e-20 + 9.287894e-20[1] 1.857579e-19x: la variable sobre la cual estamos haciendo inferencia. En este caso el promedio_académicoalternative: tipo de hipótesis alternativa. En este es una prueba bilateral usamos “two.sided”conf.level: nivel de confianza (1 - nivel de significancia = 1 - 0.05 = 0.95)mu: valor promedio de referencia. En este caso es 3.5t.test(x = datos$promedio_acad,
alternative = "two.sided",
conf.level = 0.95,
mu = 3.5)
One Sample t-test
data: datos$promedio_acad
t = 11.482, df = 92, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 3.5
95 percent confidence interval:
3.743571 3.845462
sample estimates:
mean of x
3.794516 prueba_t1 <- t.test(
x = datos$promedio_acad,
alternative = "two.sided",
conf.level = 0.95,
mu = 3.5
)
library(broom)
prueba_t1 |> tidy()wilcox.test(
x = datos$promedio_acad,
alternative = "two.sided",
conf.int = TRUE,
conf.level = 0.95,
mu = 3.5
)
Wilcoxon signed rank test with continuity correction
data: datos$promedio_acad
V = 3465.5, p-value = 6.357e-14
alternative hypothesis: true location is not equal to 3.5
95 percent confidence interval:
3.794980 3.884976
sample estimates:
(pseudo)median
3.84006 set.seed(2025)
bootstrap_promedio_udea <-
datos |>
specify(response = promedio_acad) |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "mean")
bootstrap_promedio_udeabootstrap_promedio_udea |>
visualize()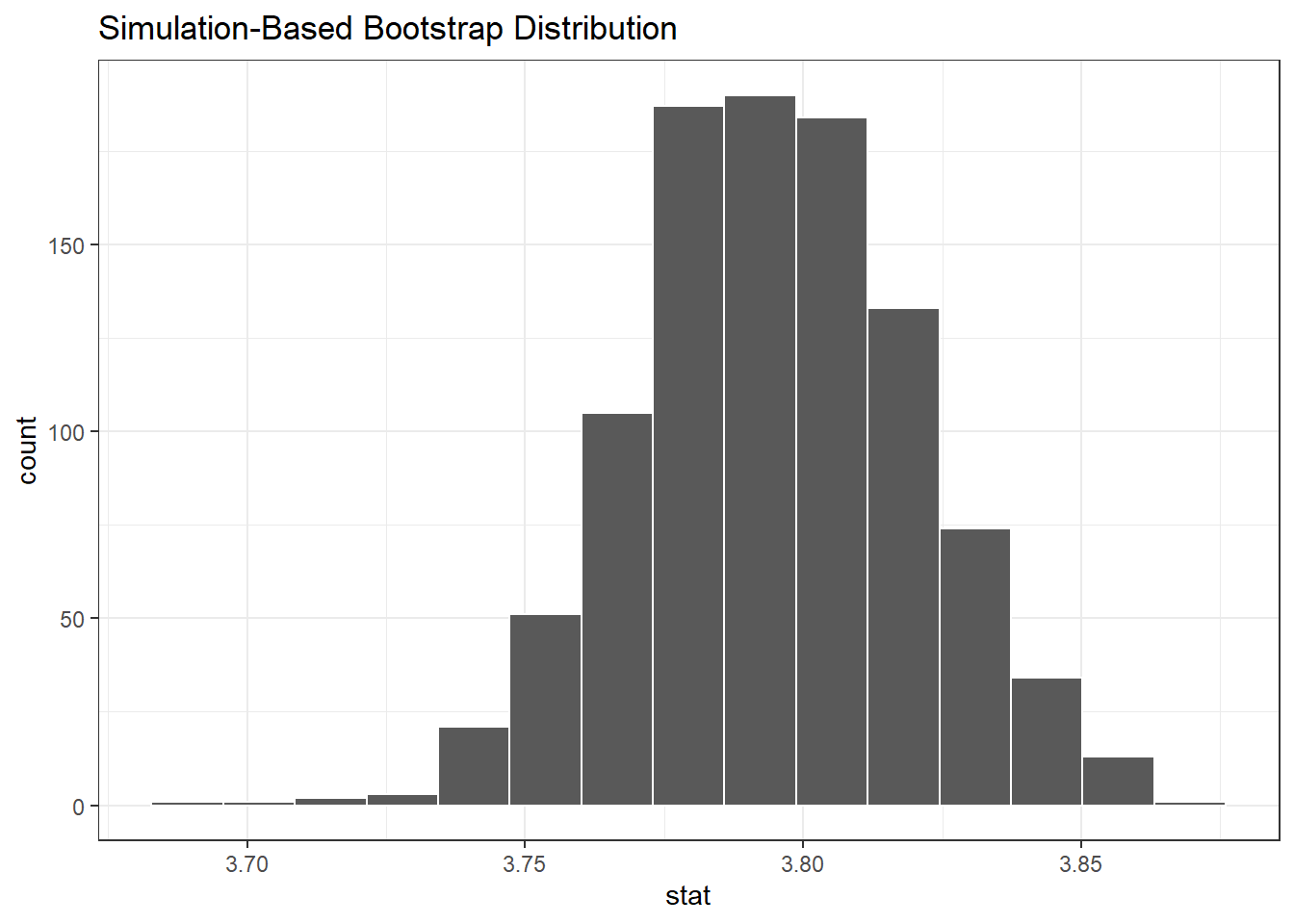

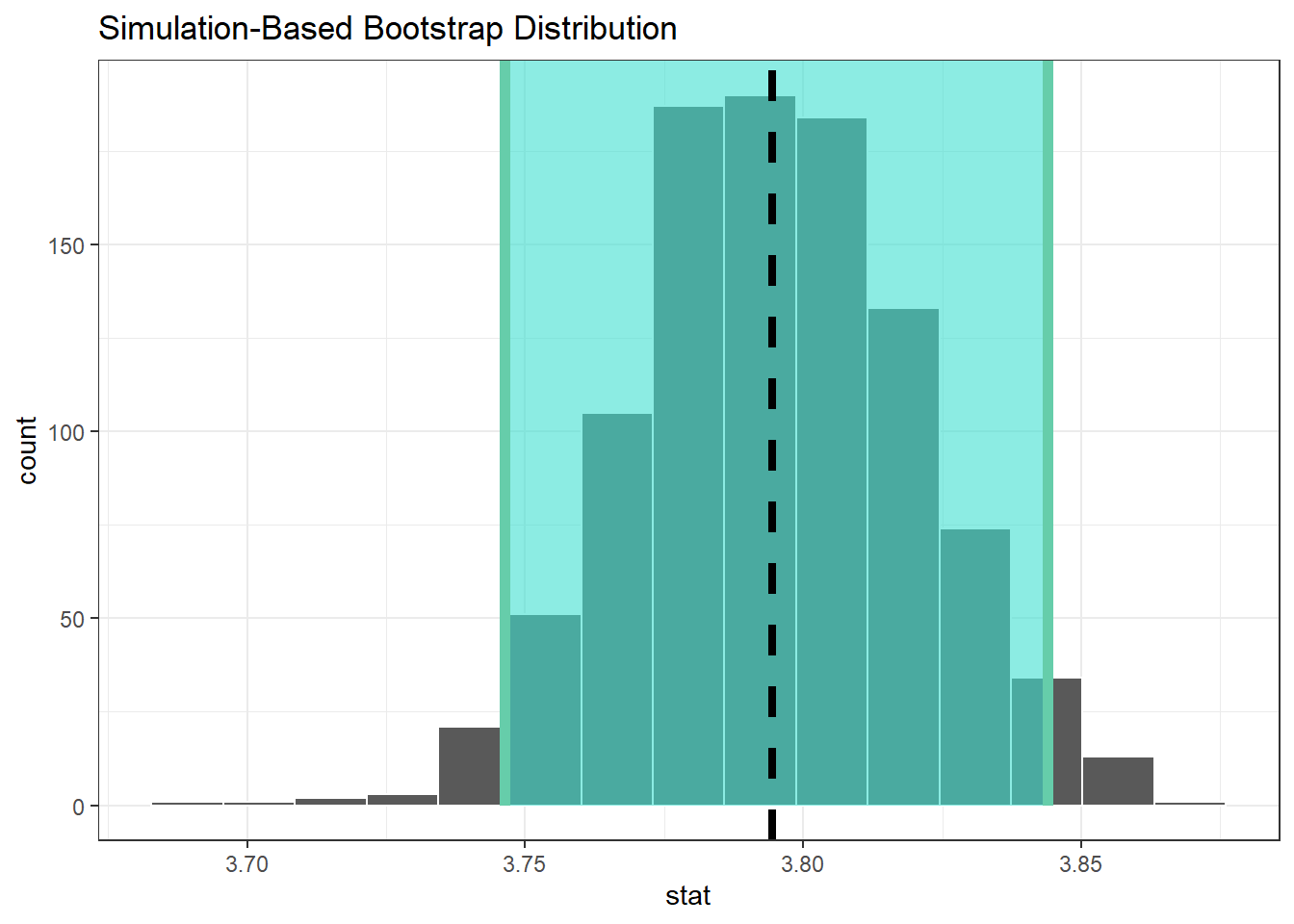
ic_promedio_percentil <-
bootstrap_promedio_udea |>
get_confidence_interval(level = 0.95, type = "percentile")
ic_promedio_percentilbootstrap_promedio_udea |>
visualize() +
shade_confidence_interval(endpoints = ic_promedio_percentil) +
geom_vline(
xintercept = x_barra,
color = "red",
lty = 2,
size = 1.5
) +
geom_vline(
xintercept = mean(datos$promedio_acad),
color = "black",
lty = 2,
size = 1.5
)
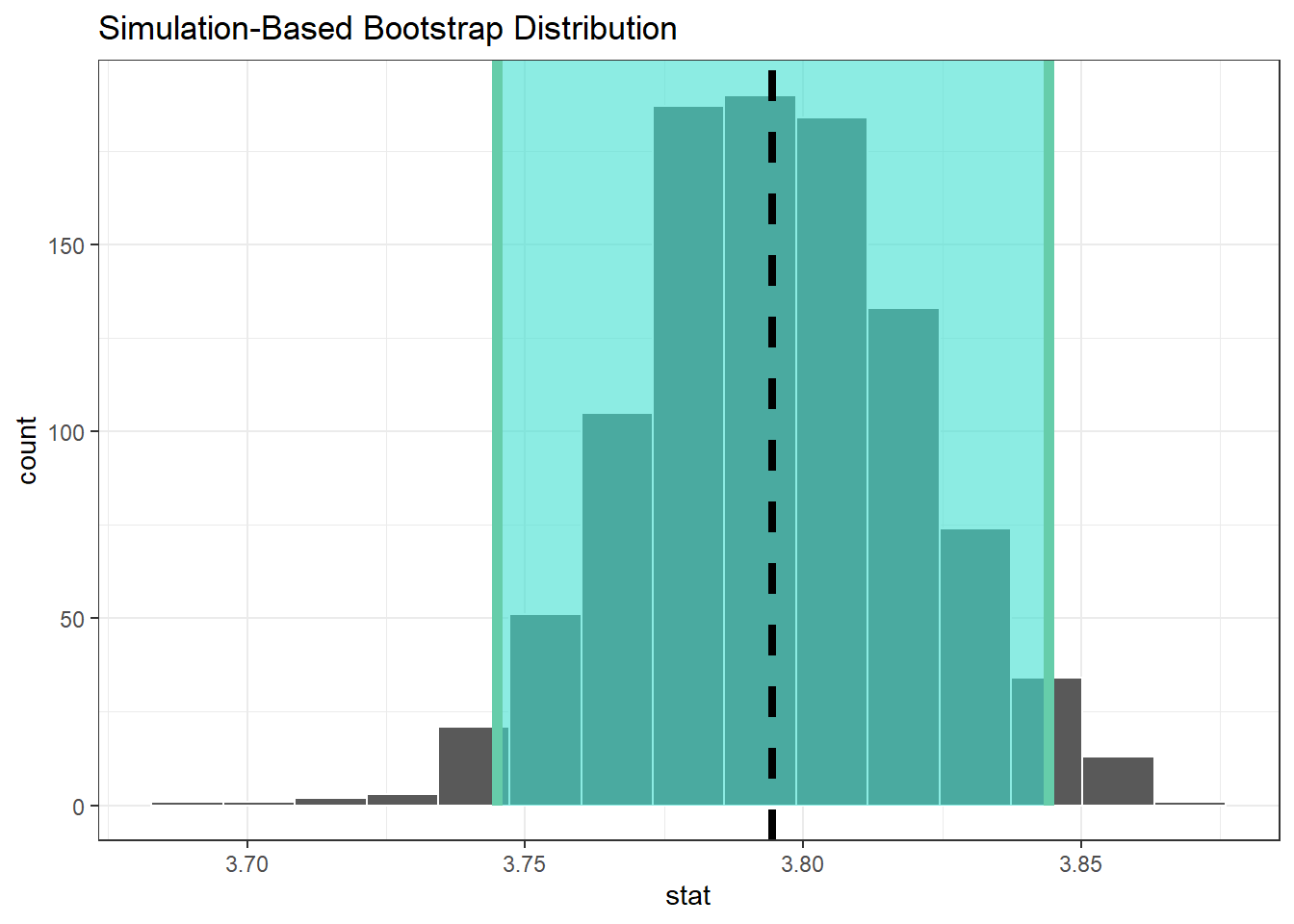
ic_promedio_error_est <-
bootstrap_promedio_udea |>
get_confidence_interval(type = "se", point_estimate = x_barra)
ic_promedio_error_estbootstrap_promedio_udea |>
visualize() +
shade_confidence_interval(endpoints = ic_promedio_error_est) +
geom_vline(
xintercept = x_barra,
color = "red",
lty = 2,
size = 1.5
) +
geom_vline(
xintercept = mean(datos$promedio_acad),
color = "black",
lty = 2,
size = 1.5
)
datos_cebada <- read_excel("datos-disexp/datos_cebada.xlsx") |>
mutate(year = as.factor(year))
datos_cebada\[H_0: \sigma^2_{1931} / \sigma^2_{1932} = 1\]
\[H_1: \sigma^2_{1931} / \sigma^2_{1932} \neq 1\]
En este caso vamos a usar un nivel de significancia del 5%.
library(ggpubr)
ggqqplot(data = datos_cebada$yield)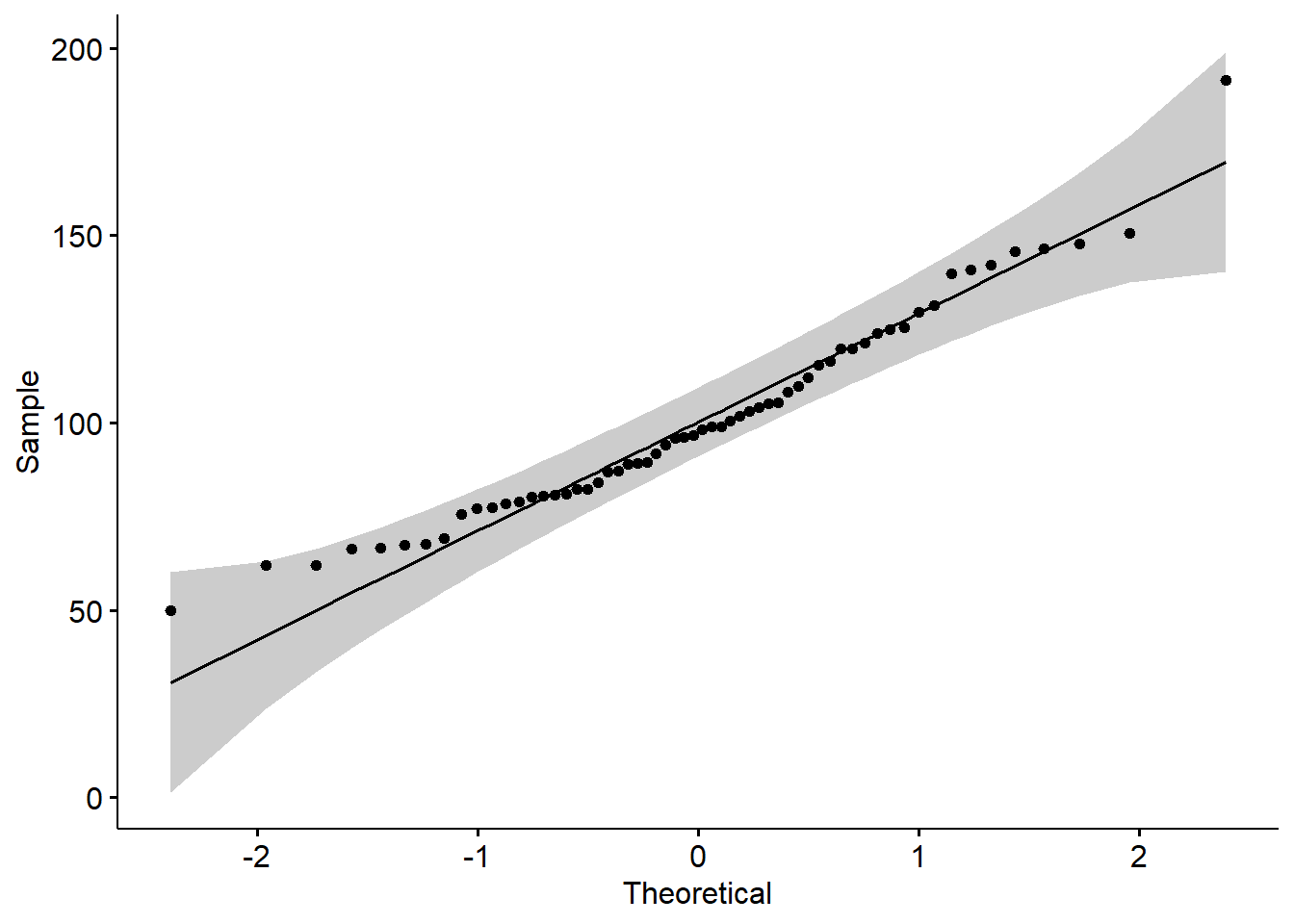
shapiro.test(x = datos_cebada$yield)
Shapiro-Wilk normality test
data: datos_cebada$yield
W = 0.96055, p-value = 0.05005formula: y ~ x. En este caso “y” es la variable produccion y el “x” es el año.ratio: es el resultado del cociente de las dos varianzas. En este caso asumimos en la hipótesis nula el valor de “1”.alternative: tipo de prueba. En este es bilateral (“two.sided”)conf.level: nivel de confianza. En este caso es 0.95 (1 - 0.5)var.test(datos_cebada$yield ~ datos_cebada$year,
ratio = 1,
alternative = "two.sided",
conf.level = 0.95)
F test to compare two variances
data: datos_cebada$yield by datos_cebada$year
F = 1.3952, num df = 29, denom df = 29, p-value = 0.375
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.6640874 2.9314037
sample estimates:
ratio of variances
1.395245 bartlett.test(datos_cebada$yield ~ datos_cebada$year)
Bartlett test of homogeneity of variances
data: datos_cebada$yield by datos_cebada$year
Bartlett's K-squared = 0.78702, df = 1, p-value = 0.375library(car)
leveneTest(datos_cebada$yield ~ datos_cebada$year)datos_trigo <- read_excel("datos-disexp/datos_trigo.xlsx")
datos_trigo\[H_0: \mu_{bajo} = \mu_{alto}\]
\[H1: \mu_{bajo} \neq \mu_{alto}\]
El juego de hipótesis anterior es equivalente al siguiente:
\[H_0: \mu_{bajo} - \mu_{alto} = 0\]
\[H1: \mu_{bajo} - \mu_{alto} \neq 0\]
nitro_bajo <- datos_trigo |> filter(nitro == "L")
nitro_alto <- datos_trigo |> filter(nitro == "H")
ggqqplot(nitro_bajo$yield)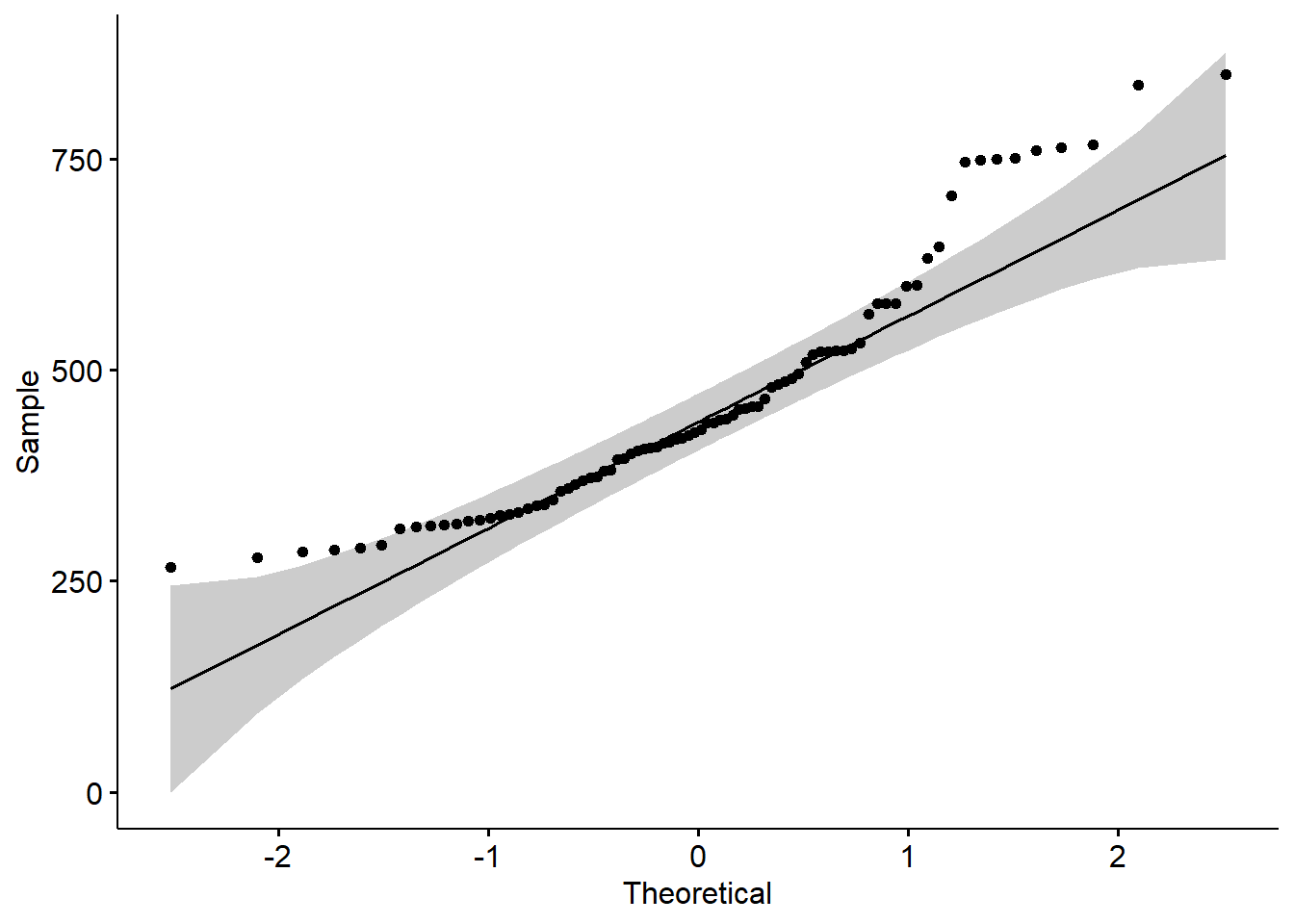
ggqqplot(nitro_alto$yield)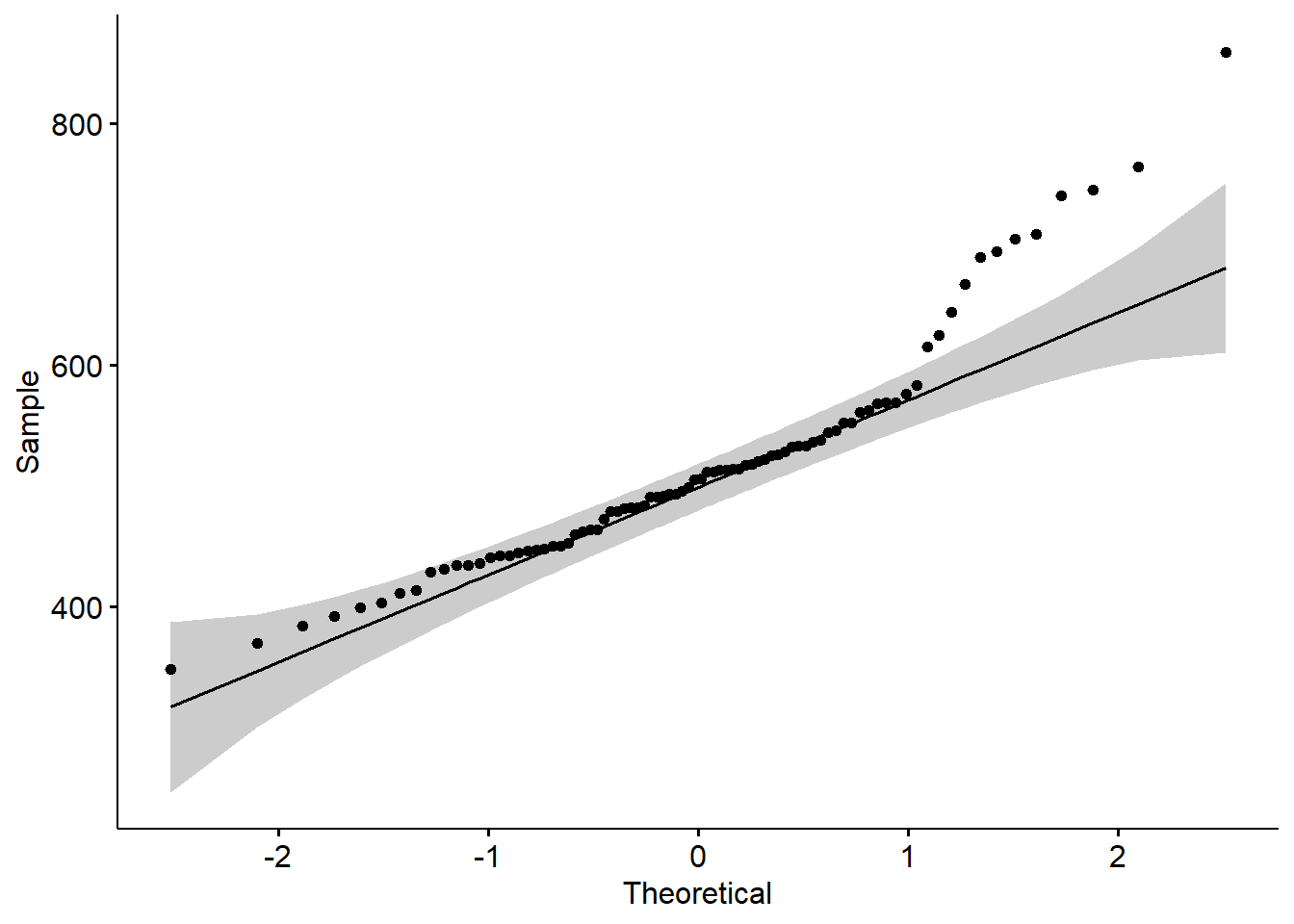
shapiro.test(nitro_alto$yield)
Shapiro-Wilk normality test
data: nitro_alto$yield
W = 0.90953, p-value = 2.064e-05shapiro.test(nitro_bajo$yield)
Shapiro-Wilk normality test
data: nitro_bajo$yield
W = 0.9039, p-value = 1.153e-05leveneTest(datos_trigo$yield ~ datos_trigo$nitro)formula: y ~ x. En este caso “y” es la producción y “x” es el nivel de fertilización con nitrógeno (bajo, alto)alternative: tipo de hipótesis alternativa. En este caso es bilateral.conf.level: nivel de confianza. En este caso es del 95%var.equal: toma valores TRUE o FALSE para cuando las varianzas son iguales o diferentes, respectivamente.t.test(datos_trigo$yield ~ datos_trigo$nitro,
alternative = "two.sided",
conf.level = 0.95,
var.equal = FALSE)
Welch Two Sample t-test
data: datos_trigo$yield by datos_trigo$nitro
t = 2.9051, df = 143.36, p-value = 0.004254
alternative hypothesis: true difference in means between group H and group L is not equal to 0
95 percent confidence interval:
17.44086 91.70200
sample estimates:
mean in group H mean in group L
517.4762 462.9048 \[H_0: p1 = p2\] \[H_1: p1 \neq p2\]
O de forma equivalente:
\[H_0: p1 - p2 = 0\]
\[H_1: p1 - p2 \neq 0\]
En este caso usaremos un nivel de significancia del 5% (0.05)
table(datos$trabaja)
No Sí
71 22 x: el número de éxitos para el evento de interés. En este caso son estudiantes que trabajan (n = 21) y no trabajan (n = 71)n: total de ensayos (observaciones). En este caso equivale a 93.alternative: tipo de hipótesis alternativa. En este caso es “two.sided”conf.level: nivel de confianza. En este caso es 1 - 0.05 = 0.95prop.test(x = c(21, 71),
n = c(93, 93),
alternative = "two.sided",
conf.level = 0.95)
2-sample test for equality of proportions with continuity correction
data: c(21, 71) out of c(93, 93)
X-squared = 51.64, df = 1, p-value = 6.666e-13
alternative hypothesis: two.sided
95 percent confidence interval:
-0.6695517 -0.4057172
sample estimates:
prop 1 prop 2
0.2258065 0.7634409 calificaciones <- read_excel("datos-disexp/datos_parciales.xlsx")
calificaciones\[H_0: \mu_{post} - \mu_{pre} = 0\]
\[H_1: \mu_{post} - \mu_{pre} \neq 0\]
En este caso vamos a usar un nivel de significancia del 5% (0.05)
diferencia <- calificaciones$Post - calificaciones$Pre
diferencia [1] 4 4 1 2 -3 5 3 2 -4 2 1 -1 2 7 0 4 6 3 4 -1ggqqplot(data = diferencia)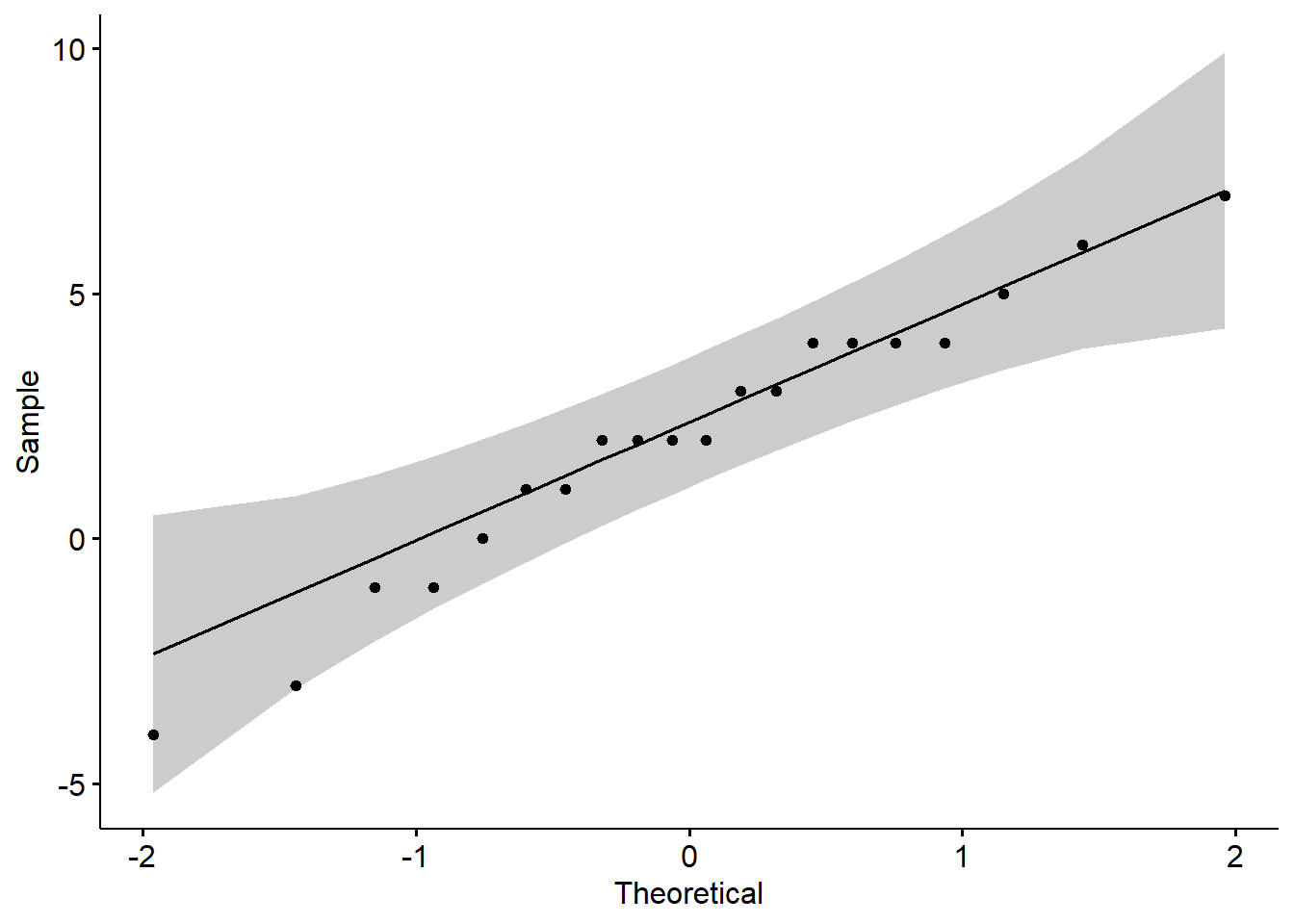
shapiro.test(x = diferencia)
Shapiro-Wilk normality test
data: diferencia
W = 0.9686, p-value = 0.725var.test(x = calificaciones$Pre,
y = calificaciones$Post,
ratio = 1,
alternative = "two.sided",
conf.level = 0.95)
F test to compare two variances
data: calificaciones$Pre and calificaciones$Post
F = 0.60329, num df = 19, denom df = 19, p-value = 0.2795
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.238790 1.524186
sample estimates:
ratio of variances
0.6032913 t.test(x = calificaciones$Pre,
y = calificaciones$Post,
alternative = "two.sided",
conf.level = 0.95,
paired = TRUE,
var.equal = TRUE)
Paired t-test
data: calificaciones$Pre and calificaciones$Post
t = -3.2313, df = 19, p-value = 0.004395
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-3.3778749 -0.7221251
sample estimates:
mean difference
-2.05 